Back to Bayes' Theorem
John Melesky (Open Source Bridge, June 2009)
Something which classifies based on:
Let's check Wikipedia.
3% of the population are using Zopadrine.
We have a drug test with a 98% accuracy rate.
3% of the population are using Zopadrine.
We have a drug test with a 98% accuracy rate.
Bob is tested, and the result is positive. How likely is it that Bob uses Zopadrine?
Let's assume a population of 10000 people.
3% are users.
| Population | |
| Clean | 9700 |
| Users | 300 |
| Total | 10000 |
The test is 98% accurate.
| Population | Test negative | Test positive | |
| Clean | 9700 | 9506 | 194 |
| Users | 300 | 6 | 294 |
| Total | 10000 | 9512 | 488 |
Bob is tested, and the result is positive. How likely is it that Bob uses Zopadrine?
| Population | Test negative | Test positive | |
| Clean | 9700 | 9506 | 194 |
| Users | 300 | 6 | 294 |
| Total | 10000 | 9512 | 488 |
294 / 488 = 60.24%
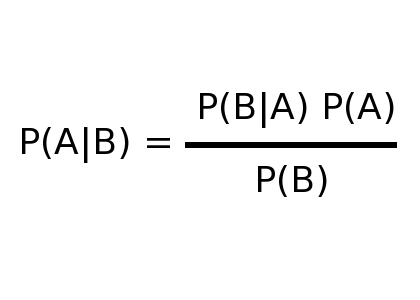
| P = probability | |
| A = "is a user" | |
| B = "tests positive" | |
| x|y = x, given y |
| P(A) = probability of being a user | |
| P(B|A) = probability of testing positive, given being a user | |
| P(B) = probability of testing positive | |
| P(A|B) = probability Bob's a user |
| P(A) = 3% | |
| P(B|A) = probability of testing positive, given being a user | |
| P(B) = probability of testing positive | |
| P(A|B) = probability Bob's a user |
| P(A) = 3% | |
| P(B|A) = 98% | |
| P(B) = probability of testing positive | |
| P(A|B) = probability Bob's a user |
| Population | Test negative | Test positive | |
| Clean | 9700 | 9506 | 194 |
| Users | 300 | 6 | 294 |
| Total | 10000 | 9512 | 488 |
| P(A) = 3% | |
| P(B|A) = 98% | |
| P(B) = 4.88% | |
| P(A|B) = probability Bob's a user |
| P(A) = 3% | |
| P(B|A) = 98% | |
| P(B) = 4.88% | |
| P(A|B) = (98% * 3%)/4.88% = 60.24% |
P(A) = 300
P(B|A) = 9800
P(B) = 488
P(A|B) = 6024
Which is useful for reasons we'll see later.
My examples are going to be in perl.
sub bayes {
my ($p_a, $p_b, $p_b_a) = @_;
my $p_a_b = ($p_b_a * $p_a) / $p_b;
return $p_a_b;
}
But you could just as easily work in Python.
def bayes(p_a, p_b, p_b_a):
return (p_b_a * p_a) / p_b
Or Java
public static Double bayes(Double p_a, Double p_b, Double p_b_a) {
Double p_a_b = (p_b_a * p_a) / p_b;
return p_a_b;
}
Or SML
let bayes(p_a, p_b, p_b_a) = (p_b_a * p_a) / p_b
Or Erlang
bayes(p_a, p_b, p_b_a) ->
(p_b_a * p_a) / p_b.
Or Haskell
bayes p_a p_b p_b_a = (p_b_a * p_a) / p_b
Or Scheme
(define (bayes p_a p_b p_b_a)
(/ (* p_b_a p_a) p_b))
LOLCODE, anyone? Befunge? Unlambda?
If it supports floating point operations, you're set.
A = "is spam"
B = "contains the string 'viagra'"
What's P(A|B)?
Fancy perl
sub tokenize {
my $contents = shift;
my %tokens = map { $_ => 1 } split(/\s+/, $contents);
return %tokens;
}
sub tokenize_file {
my $filename = shift;
my $contents = '';
open(FILE, $filename);
read(FILE, $contents, -s FILE);
close(FILE);
return tokenize($contents);
}
This is the "bag of words" model.
For each category (spam, not spam), we need to know how many documents in the training set contain a given word.
my %spam_tokens = ();
my %notspam_tokens = ();
foreach my $file (@spam_files) {
my %tokens = tokenize_file($file);
%spam_tokens = combine_hash(\%spam_tokens, \%tokens);
}
foreach my $file (@notspam_files) {
my %tokens = tokenize_file($file);
%notspam_tokens = combine_hash(\%notspam_tokens, \%tokens);
}
sub combine_hash {
my ($hash1, $hash2) = @_;
my %resulthash = %{ $hash1 };
foreach my $key (keys(%{ $hash2 })) {
if ($resulthash{$key}) {
$resulthash{$key} += $hash2->{$key};
} else {
$resulthash{$key} = $hash2->{$key};
}
}
return %resulthash;
}
my %total_tokens = combine_hash(\%spam_tokens, \%notspam_tokens);
my $total_spam_files = scalar(@spam_files);
my $total_notspam_files = scalar(@notspam_files);
my $total_files = $total_spam_files + $total_notspam_files;
my $probability_spam = $total_spam_files / $total_files;
my $probability_notspam = $total_notspam_files / $total_files;
In this case, our model is just a bunch of numbers.
In this case, our model is just a bunch of numbers.
(a little secret: it's all a bunch of numbers)
my %test_tokens = tokenize_file($test_file);
foreach my $token (keys(%test_tokens)) {
if (exists($total_tokens{$token})) {
my $p_t_s = (($spam_tokens{$token} || 0) + 1) /
($total_spam_files + $total_tokens);
$spam_accumulator = $spam_accumulator * $p_t_s;
my $p_t_ns = (($notspam_tokens{$token} || 0) + 1) /
($total_notspam_files + $total_tokens);
$notspam_accumulator = $notspam_accumulator * $p_t_ns;
}
}
my $score_spam = bayes( $probability_spam,
$total_tokens,
$spam_accumulator );
my $score_notspam = bayes( $probability_notspam,
$total_tokens,
$notspam_accumulator );
my $likelihood_spam = $score_spam / ($score_spam + $score_notspam);
my $likelihood_notspam = $score_notspam / ($score_spam + $score_notspam);
printf("likelihood of spam email: %0.2f %%\n", ($likelihood_spam * 100));
We want to use the tokens with the highest information values. That means tokens that are predominantly in one category but not the other.
We want to use the tokens with the highest information values. That means tokens that are predominantly in one category but not the other.
There are a bunch of ways to calculate this, though the big one is Information Gain.
"wrestling", "wrestler", "wrestled", and "wrestle" are all the same word concept.
Pros: fewer tokens, related tokens match
Cons: some words are hard to stem correctly (e.g. "cactus")
Bigrams are token pairs. For example, "open source", "ron paul", "twitter addict".
Pros: we start distinguishing between Star Wars and astronomy wars
Cons: our memory use balloons
Instead of binary (word x is in doc y), we store frequencies (word x appears z times in doc y).
Pros: damage from weak associations is reduced; easier to find the important words in a document
Cons: the math becomes more complex; in many cases, accuracy doesn't actually increase
Sometimes we want to use non-textual attributes of documents. For example, length of document, percent of capital letters.
Sometimes we want to use non-textual attributes of documents. For example, length of document, percent of capital letters.
We can also grab structural information, like the sender, or subject line, and treat them differently. Or whether the word appears early or late in the document.
Sometimes we want to use non-textual attributes of documents. For example, length of document, percent of capital letters.
We can also grab structural information, like the sender, or subject line, and treat them differently. Or whether the word appears early or late in the document.
Pros: a little can go a long way
Cons: selecting these can be a dark art. or an incredible memory burden.
Tokenization == Vectorization
Our documents are all just vectors of numbers.
Our documents are all just points in a high-dimensional Cartesian space.
This concept opens up a whole world of statistical methods for categorization, including decision trees, linear separations, and support vector machines.
And this opens up a whole different world of geometric methods for categorization and information manipulation, including k-nearest-neighbor classification and various clustering algorithms.
It's been a long trip. Any questions?
Thanks for coming. Thanks to OS Bridge for having me.